OpenAI, créateur du célébrissime ChatGPT, est à l’origine de Whisper, un système de reconnaissance automatique de la parole (ASR), qu’il a rendu open source en septembre 2022 pour permettre au projet de se développer plus rapidement.
Architecture de Whisper
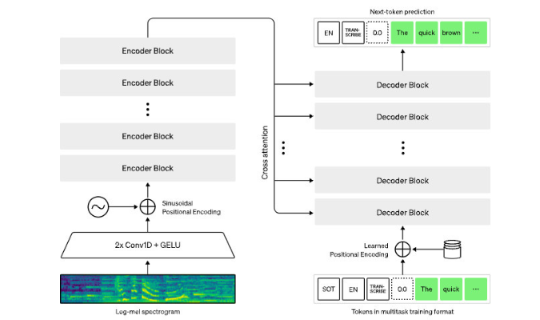
o Whisper utilise une architecture end-to-end simple, sous forme d’un Transformateur encodeur-décodeur.
o Le flux de travail est le suivant :
- L’audio d’entrée est divisé en segments de 30 secondes.
- Ces segments sont convertis en spectrogrammes log-Mel qui, pour faire simple, imite la façon dont l'oreille humaine répond à différentes fréquences.
- Ils sont ensuite envoyés dans un encodeur.
- Un décodeur est entraîné pour prédire le texte correspondant, avec des tokens spéciaux pour effectuer des tâches telles que l’identification de la langue, les horodatages au niveau des phrases, la transcription multilingue et la traduction de la parole vers l’anglais.